Sed und Awk¶
Unter den vielen Werkzeugen, die in Shell-Skripten eingesetzt werden können,
befinden sich auch die zwei Programme sed und awk, die sich auf sehr
vielseitige Art einsetzen lassen daher in diesem Abschnitt gesondert beschrieben
haben.
Sed¶
Sed steht für „Stream Editor“, ist also ein Werkzeug zum Verarbeiten von
Datenströmen dar. Im Wesentlichen wird sed also verwendet, um mit
minimalistischer Syntax exakt auf die jeweilige Aufgabe zugeschnittene
Textmanipulationen vorzunehmen. Im folgenden werden einige Einsatzmöglichkeiten
der auf Debian, Ubuntu und Linux Mint üblichen Version von sed (GNU sed)
kurz vorgestellt.

Die allgemeine Sed-Syntax lautet:
sed [-optionen] Anweisungen [Dateien]
Die einzelnen sed-Anweisungen sollten in einfach Anführungszeichen gesetzt
werden, um automatische Ersetzungen durch den Shell-Interpreter zu vermeiden.
Sollen mehrere Anweisungen ausgeführt werden, so müssen diese mittels einem
Strichpunkt (;) getrennt werden und sed mit der Option -e aufgerufen
werden.
Wird bei einem sed-Aufruf kein Dateiname angegeben, so wird automatisch Text
von der Standard-Eingabe eingelesen. Auf diese Weise kann sed in Kombination
mit einer Pipe verwendet werden, um die Ausgabe eines anderen
Programms zu bearbeiten:
# Lesen von der Standard-Eingabe mittels Pipe:
programmname | sed [-optionen] Anweisungen
Üblicherweise gibt sed seine Ergebnisse wiederum auf der Standard-Ausgabe
aus. Mit der Angabe von > dateiname als letztes übergebenes Argument oder
auch mittels einer weiteren Pipe und dem Programm tee kann die
Ausgabe jedoch auch in Textdateien umgelenkt werden:
# Lesen von der Standard-Eingabe, Ausgabe in Textdatei:
programmname | sed [-optionen] Anweisungen > dateiname
Ebenso können mittels >> dateiname als letztes Argument die Ergebnisse eines
sed-Aufrufs auch an das Ende einer (möglicherweise bereits existierenden)
Datei angehängt werden.
Optionen von sed
In der folgenden Tabelle sind die wichtigsten Optionen von sed aufgelistet:
| Option | Bedeutung |
-e anweisung1-e anweisung2 ... |
Mehrere Anweisungen nacheinander ausführen. Alternativ dazu kann eine einzelne Anweisung formuliert werden, die mehrere durch Strichpunkte getrennte Teilanweisungen umfasst. |
-f skriptdatei |
Anweisungen aus der angegebenen Skriptdatei anstelle von der Standard-Eingabe lesen |
-i |
Änderungen direkt in angegebene Dateien schreiben („in-place-editing“) |
-n |
Ergebnisse nur dann ausgeben, wenn dies mit der Anweisung p explizit
verlangt wird. |
Wird mittels -f eine Skriptdatei (übliche Endung: .sed) angegeben, so
wird in dieser üblicherweise eine sed-Anweisung je Zeile formuliert, eine
Trennung einzelner Anweisungen durch Strichpunkte kann in diesem Fall entfallen.
Zusätzlich können in eine derartige Skriptdatei Kommentare eingefügt werden,
die aus eigenen, mittels des Zeichens # eingeleiteten Zeilen bestehen.
Anweisungen von sed
Die wohl häufigste Anwendung von sed besteht darin, einzelne Wörter oder
reguläre Ausdrücke durch andere Begriffe zu ersetzen. Die entsprechende
sed-Anweisung heißt s („substitute“). Ihre Syntax lautet etwa wie
folgt:
sed 's/alt/neu/g'
Die obige Anweisung würde im gesamten an sed übergebenen Text nach dem
Begriff alt suchen und diesen durch neu ersetzen. Das Schlüsselzeichen
g („global“) am Ende der Anweisung bewirkt, dass nicht nur das erste,
sondern alle Vorkommen von alt durch neu ersetzt werden sollen.[1]
Sollen Ersetzungen in Textstellen vorgenommen werden, die selbst Schrägstriche
beinhalten (beispielsweise Pfadangaben), so kann anstelle von / auch ein
anderes Zeichen als Trennzeichen verwendet werden. Der gleiche Aufruf von Sed
sieht beispielsweise mit # als Trennzeichen so aus:
sed 's#alt#neu#g'
Möchte man die Ersetzungen nur in einem bestimmten Bereich, beispielsweise
zwischen zwei Zeilennummern, vornehmen, so ist eine Bereichsangabe unmittelbar
zu Beginn der sed-Anweisung möglich. Diese kann aus einer einzelnen Adresse
oder auch zwei Adressen, die einen Bereich markieren, bestehen:
# In der Zeile 5 "alt" durch "neu" ersetzen:
5s/alt/neu/g
# In den Zeilen 10-30 "alt" durch "neu" ersetzen:
10,30s/alt/neu/g
Bei einer Bereichsangabe kann auch eine der beiden Adressen weggelassen werden, um eine Ersetzung vom Anfang des Textes bis zu einer beziehungsweise ab einer gegebenen Stelle bis zum Ende des Textes zu erreichen:
# Ab Zeile 10 "alt" durch "neu" ersetzen:
10,s/alt/neu/g
# Bis Zeile 30 "alt" durch "neu" ersetzen:
,30s/alt/neu/g
Bereichsangaben können durch ein angefügtes Ausrufezeichen (!) umgekehrt
werden. Die Anweisung bezieht sich dann auf alle Zeilen, die außerhalb der
Bereichsangabe liegen:
# In allen Zeilen außer 10-30 "alt" durch "neu" ersetzen:
10,30!s/alt/neu/g
Anstelle von Zeilenangaben können Adressen auch aus Suchmustern bestehen, die ebenfalls zwischen zwei Schrägstrichen angegeben werden:
# In allen Zeilen, die "total" enthalten, alt" durch "neu" ersetzen:
/total/s/alt/neu/g
# Zwischen "START" und "END" alle Vorkommnisse von alt" durch "neu" ersetzen:
/START/,/END/s/alt/neu/g
Auch Bereichsangaben, die aus Suchmustern bestehen, können mittels einem Ausrufezeichen negiert werden. Sowohl in den Bereichsangaben wie ich in den zu ersetzenden Begriffen können zudem reguläre Ausdrücke eingesetzt werden.
Weitere gebräuchliche Anweisungen von sed sind in der folgenden Tabelle
aufgelistet:
| Anweisung | Bedeutung |
a |
An die angegebene(n) Stelle(n) den folgenden Text als neue Zeile anfügen („append“). Beispiel: |
c |
Die angegebene(n) Stelle(n) durch den folgenden Text als neue Zeile ersetzen („change“). Beispiel: |
i |
Vor den angegebene(n) Stelle(n) den folgenden Text als neue Zeile einfügen („insert“). Beispiel: |
d |
Die angegebene(n) Stelle(n) löschen („delete“) Beispiel: |
p |
Gibt die angegebene(n) Stelle(n) aus („print“); wird üblicherweise in
Kombination mit der Option -n verwendet. |
q |
Sed innerhalb einer Skriptdatei beenden („quit“). |
r |
Vor den angegebene(n) Stelle(n) den Inhalt der folgenden Datei einfügen („read“). Beispiel: |
y |
An den angegebene(n) Stelle(n) Zeichen aus einer Liste durch andere Zeichen ersetzen („yank“). Beispiel: |
w |
Schreibt die angegebene(n) Stelle(n) in die folgende Datei („write“). Beispiel: |
Weitere Funktionen von sed sind in den Manpages beschrieben (man sed).
Reguläre Ausdrücke für Sed
In Bereichsangaben, Suchmustern und Ersetzungen können in sed so genannte
reguläre Ausdrücke eingesetzt werden. Dabei handelt es sich um Kombinationen von
normalen Buchstaben und Sonderzeichen, die eine besondere Bedeutung besitzen.
Die wichtigsten Sonderzeichen sind in der folgenden Tabelle aufgelistet.
| Sonderzeichen | Bedeutung |
^ |
Zeilenanfang |
$ |
Zeilenende |
. |
ein beliebiges Zeichen (außer dem Newline-Zeichen \n) |
[A-Z] |
ein Großbuchstabe |
[a-z] |
ein Kleinbuchstabe |
[0-9] |
eine Ziffer |
[abc123] |
ein Zeichen aus der angegebenen Menge an Buchstaben oder Ziffern |
[^abc123] |
ein beliebiges Zeichen außer der angegebenen Menge an Buchstaben oder Ziffern |
\( \) |
Gruppierung der zwischen den Klammern angegebenen Zeichen zu einem einzigen Ausdruck. Die Textstellen, auf welche die einzelnen Gruppierungen zutreffen,
können bei Ersetzungen mittels |
\{m,n\} |
mindestens Mit |
* |
keine, eine oder beliebig viele Wiederholungen des vorhergehenden Zeichens oder der vorangehenden Gruppierung |
\< \> |
Wortanfang und Wortende |
& |
Bei Ersetzungen entspricht & der gesamten Textstelle, auf welche das
angegebene Suchmuster zugetrifft. |
In eckigen Klammern kann zur Definition einer Charakter-Klasse auch auch ein
anderer Bereich angegeben werden; beispielsweise bezeichnet [a-m] einen
Kleinbuchstaben zwischen a und m. Soll ein Zeichen mit Sonderbedeutung,
beispielsweise ein Dollar- oder ein Punkt-Zeichen Teil eines regulären Ausdrucks
sein, so muss davor ein Backslash-Zeichen gesetzt werden, um die Sonderbedeutung
des Zeichens aufzuheben.
Links
Awk¶
Awk wird bevorzugt verwendet, um tabularische Daten zeilenweise einzulesen und dabei einzelne Zeilen, die bestimmte Muster enthalten, zu bearbeiten. Jedes Awk-Skript, das oftmals nur wenige Zeilen umfasst, besteht also aus Mustern und zugehörigen Aktionen.
Als Suchmuster werden, wie bei Sed, oftmals reguläre Ausdrücke genutzt. Die Formulierung der zugehörigen Aktionen hat einige Ähnlichkeiten mit der Programmiersprache C. Awk nimmt dem Benutzer allerdings viel Arbeit ab: Es liest den Eingabetext automatisch zeilenweise ein und zerlegt jede Zeile anhand eines frei wählbaren Trennzeichens in einzelne Felder (Spalten).
Einfache Awk-Skripte
Einfache Awk-Skripte sind oftmals folgendermaßen aufgebaut:
awk [optionen] '/muster/ {print ...}' dateiname
Das angegebene Muster kann eine einfache Zeichenkette, aber auch ein regulärer Ausdruck oder eine Bedingung sein. Im obigen Fall würde damit die angegebene Datei zeilenweise eingelesen und einzelne Teile jeder auf das Muster zutreffenden Zeile ausgegeben.
Die einzelnen Felder einer Zeile werden von Awk mit $1 bis $9
durchnummeriert, $0 steht für den gesamten Inhalt einer Zeile. Möchte man
beispielsweise von allen Zeilen einer Datei nur die ersten drei Spalte ausgeben,
so kann das Muster auch weggelassen werden:
# Awk-Print-Anweisung auf alle Zeilen einer Datei anwenden:
awk '{print $1 $2 $3}' dateiname
Ebenso kann Awk mittels einer Pipe Ausgabedaten eines anderen Programms als Eingabe verwenden. In diesem Fall kann der Dateiname weggelassen werden:
# Daten vom Bildschirm anstelle von einer Datei einlesen:
other_programm | awk '/muster/ {anweisungen}'
Üblicherweise werden von awk so genannte „Whitespace“-Zeichen, also
Leerzeichen und Tabulator-Zeichen (\t), als Trennzeichen zwischen den
einzelnen Feldern einer Zeile interpretiert. Möchte man beispielsweise bei der
Verarbeitung einer .csv-Datei („Comma Seperated Values“) das Zeichen ,
oder ; als Trennzeichen verwenden, so kann dies mittels der Option -F
(„Field Seperator“) angegeben werden:
# Das Zeichen ";" als Feldtrennzeichen verwenden:
awk -F ";" '/muster/ {anweisungen}' dateiname
In einem Awk-Skript können auch mehrere Muster-Anweisungs-Paare in folgender Form angegeben werden:
# Mehrere Muster-Anweisungspaare angeben:
awk [optionen] '/muster1/ {anweisung1} /muster2/ {anweisung2} ...' dateiname
In einer Shellskript-Datei können die einzelnen Anweisungen zur besseren Lesbarkeit auch untereinander geschrieben werden:
# Mehrere Muster-Anweisungspaare, andere Form:
awk [optionen] '/muster1/ {anweisung1}
/muster2/ {anweisung2}
... ' dateiname
In diesem Fall wird bei jeder eingelesenen Zeile zunächst das erste Muster geprüft und gegebenenfalls der zugehörige Anweisungsblock ausgeführt. Wenn das erste Muster nicht zutrifft, wird geprüft, ob das zweite Muster zutrifft, usw. Sobald ein Muster zutrifft, werden also die entsprechenden Anweisungen ausgeführt, und Awk fährt mit dem Einlesen der nächsten Zeile fort. Die einzelnen Muster-Anweisungs-Paare werden somit als einander ausschließende Entweder-Oder-Abfragen interpretiert. Das vorrangige Suchmuster muss also an erster Stelle stehen, da es sonst gegebenenfalls nicht ausgeführt wird.
Soll ein Anweisungsblock ausgeführt werden, wenn wahlweise das eine und/oder ein anderes Muster auftritt, so können diese in folgender Form angeben werden:
# Ausführung, wenn muster1 oder muster2 oder beide zutreffen:
awk [optionen] '/muster1/ || /muster2/ {anweisungen}' dateiname
Das Zeichen || entspricht somit, ebenso wie in der Programmiersprache C,
einem logischen ODER. Soll ein Anweisungsblock hingegen nur dann ausgeführt
werden, wenn sowohl das eine als auch das andere Muster auftritt, so kann
folgende Syntax verwendet werden:
# Ausführung nur, wenn sowohl muster1 und muster2 zutreffen:
awk [optionen] '/muster1/ && /muster2/ {anweisungen}' dateiname
Das Zeichen && entspricht, ebenso wie in C, einem logischen UND. Mittels
|| beziehungsweise && können auch mehr als zwei (Teil-)Muster kombiniert
werden; bei Bedarf können runde Klammern gesetzt werden, um die gewünschte
Kombination der Ausdrücke zu erreichen (siehe Aussagenlogik).
BEGIN- und END-Anweisungen
In Awk kann man je einen Anweisungsblock einmalig zu Beginn beziehungsweise
einmalig am Ende eines Skripts ausführen. BEGIN-Anweisungen können
beispielsweise dazu genutzt werden, um Header-Zeilen in eine Ausgabe-Datei zu
schreiben, bevor die eigentlichen Daten verarbeitet werden.
awk 'BEGIN {anweisungen} /muster/ {anweisungen}' dateiname
Entsprechend können mittels einer END-Anweisung zusätzliche Informationen
am Ende der Datenverarbeitung ausgegeben werden:
awk '/muster/ {anweisungen} END {anweisungen}' dateiname
END-Anweisungen sind insbesondere praktisch, wenn mehrere Werte summiert
werden und das Ergebnis am Ende ausgegeben werden soll. Dies ist, wie im
nächsten Abschnitt beschrieben, durch die Verwendung von Variablen möglich.
Variablen und arithmetische Operationen
In Awk lassen sich auf sehr einfache Weise einzelne Werte in Variablen speichern. Dazu wird folgende Syntax verwendet:
varname=wert
Die Definition einer Variablen kann an jeder beliebigen Stelle innerhalb eines
Awk-Skripts erfolgen. Mittels print varname kann der gespeicherte Wert
wieder ausgegeben werden. Die Variablen $0 für den Inhalt der aktuellen
Zeile sowie die Variablen $1 bis $9 für die einzelnen Felder der
aktuellen Zeile sind bereits vordefiniert.
In Awk werden alle Variablen als Zeichenketten interpretiert. Dennoch können
einfache arithmetische Operationen auf Variablen angewendet werden;
beispielsweise kann mit awk '{prod=$1*$2 ; print $1 $2 prod}' eine
zweispaltige Datentabelle um eine dritte Spalte ergänzt werden, deren Werte in
jeder Zeile dem Produkt der ersten beiden Spalten entspricht.[2]
Einer Variablen kann nicht nur mittels des üblichen Zuweisungsoperators =,
sondern auch beispielsweise mittels += ein Wert zugewiesen werden. Hierbei
wird der bisherige Wert der Variablen um den auf der rechten Seite stehenden
Ausdruck erhöht. Da jede neu definierte Variable in Awk zunächst den Wert Null
hat, können auf diese Weise beispielsweise alle in einer Spalte stehenden
Zahlenwerte aufaddiert werden. Das Ergebnis kann dann mittels eines
END-Blocks ausgegeben werden:
# Dateigrößen des aktuellen Verzeichnisses ausgeben:
# (Die 5. Spalte von `ls -l` gibt die Dateigröße an)
ls -l | awk '{print $5}'
# Alle Werte zur Gesamtgröße aufsummieren:
ls -l | awk '{sum += $5} END {print "Gesamt:\t" sum}'
Reguläre Ausdrücke für Awk
In den angegebenen Mustern können auch in Awk reguläre Ausdrücke eingesetzt werden; damit sind Kombinationen von normalen Buchstaben und Sonderzeichen gemeint, wobei letztere die eine besondere Bedeutung besitzen. Die wichtigsten Sonderzeichen sind in der folgenden Tabelle aufgelistet.
| Sonderzeichen | Bedeutung |
^ |
Zeilenanfang |
$ |
Zeilenende |
. |
ein beliebiges Zeichen |
[A-Z] |
ein Großbuchstabe |
[a-z] |
ein Kleinbuchstabe |
[0-9] |
eine Ziffer |
[abc123] |
ein Zeichen aus der angegebenen Menge an Buchstaben oder Ziffern. |
[^abc123] |
ein beliebiges Zeichen außer der angegebenen Menge an Buchstaben oder Ziffern |
( ) |
Gruppierung der zwischen den Klammern angegebenen Zeichen zu einem einzigen Ausdruck. |
| |
entweder der vor unmittelbar vor oder unmittelbar nach | stehende
Audruck (oder die entsprechende Gruppierung) |
+ |
eine oder beliebig viele Wiederholungen des vorhergehenden Zeichens oder der vorangehenden Gruppierung |
* |
keine, eine oder beliebig viele Wiederholungen des vorhergehenden Zeichens oder der vorangehenden Gruppierung |
? |
kein oder genau ein Vorkommen des vorhergehenden Zeichens oder der vorangehenden Gruppierung |
{m,n} |
mindestens  und höchstens und höchstens 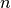 Wiederholungen des
vorhergehenden Zeichens oder der vorangehenden Gruppierung.
Mit Wiederholungen des
vorhergehenden Zeichens oder der vorangehenden Gruppierung.
Mit {m} kann die Anzahl auf genau , mit {m,} auf
mindestens festgelegt werden. |
Im Gegensatz zu den regulären Ausdrücken für Sed haben runde und geschweifte Klammern standardmäßig die oben angegebene Sonderbedeutung; soll das jeweilige Zeichen an sich Teil eines regulären Ausdrucks sein, so muss davor ein Backslash-Zeichen gesetzt werden.
Bedingungen als Muster
Nicht nur reguläre Ausdrücke, sondern auch Bedingungen können als Muster zur
Auswahl der zu bearbeitenden Zeilen genutzt werden. Sollen beispielsweise alle
Zeilen einer Tabelle ausgegeben werden, deren Wert in der dritten Spalte
 ist, so könnte man folgendes schreiben:
ist, so könnte man folgendes schreiben:
# Print-Anweisung unter einer bestimmten Bedingung ausführen:
awk '$3 >= 50 {print $0}' dateiname
Für Werte-Vergleiche können folgende Operatoren genutzt werden:
| Operator | Beschreibung |
== |
Test auf Wertgleichheit |
!= |
Test auf Ungleichheit |
< |
Test, ob kleiner |
<= |
Test, ob kleiner oder gleich |
=> |
Test, ob größer oder gleich |
> |
Test, ob größer |
Auch bei Werte-Vergleichen können mehrere Bedingungen mittels && als
UND-Verknüpfung beziehungsweise || als ODER-Verknüpfung zu einer
Gesamt-Bedingung kombiniert werden; ebenso sind Kombinationen von
Werte-Vergleichen und normalen Suchmustern oder regulären Ausdrücken möglich.
Zur Gruppierung einzelner Teilbedingungen können wiederum runde Klammern gesetzt
werden.
Der Istgleich-Operator == kann zudem verwendet werden, um eine Spalte mit
einer Zeichenkette zu vergleichen, beispielsweise $1 == "Hallo".
Links
Anmerkungen:
| [1] | Anstelle von Neben dem Schlüsselzeichen |
| [2] | Möchte man die einzelnen Spalten bei der Ausgabe durch Tabulator-Zeichen
"\t" getrennt haben, so ist dies mittels awk '{prod=$1*$2 ; print $1
"\t" $2 "\t" prod}' möglich. |