Datentypen¶
Im folgenden Abschnitt werden die zum Python-Standard gehörenden Datentypen kurz
vorgestellt. In Skripten oder im interaktiven Modus kann der Datentyp eines
Objekts oder einer Variable jederzeit mittels type(variable) angezeigt
werden.
None – Der Nichts-Typ¶
Durch den Datentyp None wird in Python beispielsweise symbolisiert, dass
eine Variable keinen Wert beinhaltet. Dies ist beispielsweise sinnvoll, wenn man
eine Variable definieren, ihr aber erst späteren einen konkreten Wert zuweisen
will; ein anderer Anwendungsfall wäre die Rückgabe eines Ergebniswerts bei einer
erfolglosen Suche.
Um einer Variablen den Wert None zuzuweisen, gibt man folgendes ein:
var_1 = None
# Test:
print(var_1)
# Ergebnis: None
None ist ein Singleton, es gibt also stets nur eine
Instanz dieses Typs; None kann somit stets wie eine Konstante verwendet
werden. Ebenso kann mittels des None-Typs abgefragt werden, ob eine Variable
einen Wert beinhaltet oder nicht. Eine solche Abfrage kann prinzipiell so
aussehen:
if var_1 is None:
print('var_1 has no value.')
else:
print('the value of var_1 is ' var_1)
Mittels des Schlüsselworts is wird im obigen Beispiel überprüft, ob
var_1 eine Instanz des Typs None ist. Durch if var_1 is not None
kann sichergestellt werden, dass ein Code-Teil nur dann ausgeführt wird, wenn
der Variablen var_1 bereits ein Wert zugewiesen wurde.
Numerische Datentypen¶
True und False – Boolesche Werte¶
Eine boolesche Variable kann nur True (wahr) oder False (falsch) als
Werte annehmen. Von Python wird True als 1 beziehungsweise False als
0 interpretiert, so dass sich theoretisch auch mit Variablen des Datentyps
bool rechnen lässt (beispielsweise ergibt True + True den Wert 2).
Der boolesche Wahrheitswert eines beliebigen Ausdrucks kann mittels der
Standard-Funktion bool() ermittelt werden, beispielsweise
liefert bool(1) den Wert True.
int – Ganze Zahlen¶
Ganzzahlige Werte werden in Python durch den Datentyp int repräsentiert.
Um die Anzahl an Ziffern einer int-Zahl zu bestimmen, kann diese mittels
str() in eine Zeichenkette umgewandelt werden; anschließend kann die
Länge dieser Zeichenkette mittels len() bestimmt werden:
num_1 = 58316
# Zahl in Zeichenkette umwandeln:
str(num_1)
# Ergebnis: '58316'
# Anzahl der Ziffern der Zahl ausgeben:
len(str(num_1))
# Ergebnis: 5
Wird im umgekehrten Fall eine Zahl beispielsweise mittels der Funktion
input() eingelesen, so liegt sie als Zeichenkette vor; mittels int() ist
dann eine Konvertierung in eine gewöhnliche Zahl möglich.
Bisweilen werden Zahlen auch in einer binären, oktalen oder hexadezimalen
Darstellung verwendet. Um eine dezimale int-Zahl mit einer anderen
Zahlenbasis (2, 8 oder 16) darzustellen, gibt es folgende Funktion:
num_1 = 78829
bin(num_1)
# Ergebnis: '0b10011001111101101'
oct(num_1)
# Ergebnis: '0o231755'
hex(num_1)
# Ergebnis: '0x133ed'
Das Ergebnis sind jeweils Zeichenketten, die mit 0b (binär), 0o (oktal)
oder 0x (hexadezimal) beginnen. Um eine derartige Zeichenkette wieder in
eine gewöhnliche int-Zahl zu konvertieren, kann man die int()-Funktion
nutzen, wobei die ursprüngliche Zahlenbasis als zweites Argument angegeben
werden muss:
# Binärzahl in Dezimalzahl umwandeln:
int('0b10011001111101101', base=2)
# Ergebnis: 78829
Um die größte beziehungsweise kleinste mindestens zweier Zahlen (int oder
float) zu bestimmen, können die Funktionen min() oder max() genutzt
werden:
min(-5, 17842, 30911, -428)
# Ergebnis: -428
max(-5, 17842, 30911, -428)
# Ergebnis: 30911
Der Absolutwert einer int oder float-Zahl kann mittels der
Standardfunktion abs(number) ausgegeben werden.
float – Gleitkommazahlen¶
Zahlen mit Nachkommastellen werden in Python durch den Datentyp float
repräsentiert. Die Nachkommastellen werden dabei – wie im englischen Sprachraum
üblich – nicht durch ein Komma, sondern durch einen Punkt . von dem
ganzzahligen Anteil getrennt. Zudem ist es möglich, sehr große oder sehr kleine
float-Zahlen mittels e oder E in Exponential-Schreibweise anzugeben.
Die Zahl hinter dem e gibt dabei an, um wie viele Stellen der Dezimalpunkt
innerhalb der Zahl verschoben wird.
4.3e5 == 430000
# Ergebnis: True
7.92e-5 == 0.0000792
# Ergebnis: True
Um eine float-Zahl auf 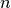 Nachkomma-Stellen zu runden, kann die
Funktion
Nachkomma-Stellen zu runden, kann die
Funktion round(float_num, n) genutzt werden. Wird das Argument n
weggelassen, wird auf die nächste ganze Zahl gerundet. Eine Gleitkommazahl
float_1 kann ebenso mittels int(float_1) in eine ganze Zahl umgewandelt
werden; dabei werden jedoch eventuell vorhandene Nachkommastellen abgeschnitten,
es also stets die betragsmäßig nächst kleinere ganze Zahl als Ergebnis zurück
gegeben.
complex – Komplexe Zahlen¶
Komplexe Zahlen bestehen aus einem Realteil und
einem Imaginärteil. Der Imaginärteil besteht aus einer reellen Zahl, die mit der
imaginären Einheit j multipliziert wird. [1]
Um eine komplexe Zahl zu definieren, gibt man in Python etwa folgendes ein:
z_1 = 4 + 3j
z_2 = 5.8 + 1.5j
Für das Arbeiten mit komplexen Zahlen kann das cmath-Modul aus der
Standardbibliothek genutzt werden.
str – Zeichenketten¶
Zeichenketten („Strings“) sind eine Folge von Zeichen, die wahlweise in
einfachen oder doppelten Anführungszeichen geschrieben werden. [2] Nahezu jedes
Python-Objekt kann mittels str(object) in eine Zeichenkette umgewandelt
werden, um beispielsweise eine druckbare Darstellung mittels print() zu
ermöglichen.
string_1 = 'Hallo'
string_2 = 'Welt!'
string_3 = str(539) # Ergebnis: '539'
Zeichenketten können mittels + miteinander kombiniert werden. Möchte man
eine Zeichenkette beliebiger Länge in mehrfacher Wiederholung, so kann diese
mittels * und einer ganzzahligen Zahl vervielfacht werden. Da Zeichenketten
in Python (wie Tupel) unveränderbar sind, wird bei den
obigen Beispielen stets eine neue Zeichenkette erzeugt. Die ursprüngliche
Zeichenkette bleibt jeweils unverändert:
string_1 + ' ' + string_2
# Ergebnis: 'Hallo Welt!'
string_1 * 3
# Ergebnis: 'HalloHalloHallo'
Die Länge einer Zeichenkette kann mittels len() bestimmt werden:
len('Hallo Welt')
# Ergebnis: 10
Zur besseren Lesbarkeit sollten Code-Zeilen allgemein nicht mehr als 80 Zeichen
lang sein. Lange Zeichenketten können allerdings in der nächsten Zeile fortgesetzt
werden, wenn die vorangehende Zeile mit einem einzelnen Backslash \ als
Zeile-Fortsetzungs-Zeichen abgeschlossen wird:
long_string = 'Das ist eine lange Zeichenkette, die für eine bessere \
Lesbarkeit über zwei Zeilen verteilt geschrieben wird.'
Durch den Backslash werden also beide Zeilen zu einer logischen Einheit verbunden; hinter dem Backslash darf allerdings kein Kommentarzeichen stehen.
Mehrzeilige Zeichenketten können ebenso in dreifache Anführungszeichen gesetzt werden. Solche „Docstrings“ werden beispielsweise verwendet, um längere Code-Abschnitte, Funktionen, Klassen oder Module zu dokumentieren, denn sie bleiben vom Interpreter unbeachtet. Beim Schreiben von Docstrings sollten die offiziellen Empfehlungen beachtet werden.
Zeichenketten können allgemein folgende Sonderzeichen beinhalten:
| Zeichen | Bedeutung |
\t |
Tabulator |
\n |
Newline (Zeilenumbruch) |
\r |
Carriage Return |
\\ |
Backslash |
\' |
Einfaches Anführungszeichen |
\" |
Doppeltes Anführungszeichen |
\xnn |
Sonderzeichen (ASCII), repräsentiert durch eine
zweistellige Hexadezimalzahl, beispielsweise \xe4 |
\unnnn |
Sonderzeichen (16-bit-Unicode), repräsentiert durch eine vierstellige
Hexadezimalzahl, beispielsweise \u7fe2 |
Möchte man das Interpretieren der obigen Sonderzeichen unterbinden, kann dies
durch ein vorangestelltes r („raw“) geschehen; beispielsweise wird in
r'a\tb' das \t nicht als Tabulator-Zeichen interpretiert.
Indizierung von Zeichenketten¶
Auf die einzelnen Zeichen einer Zeichenkette kann mittels des Index-Operators
[ ] zugegriffen werden. Dabei wird das erste Zeichen, wie in der
Programmiersprache C üblich, mit 0 indiziert. Auf das letzte Element
eines Zeichen langen Strings kann entsprechend mit dem Index n-1,
oder in Kurzschreibweise mit dem Index -1 zugegriffen werden. Ein größerer
Index als n-1 löst einen Fehler (IndexError) aus.
example = 'Hallo Welt'
# Erstes und zweites Zeichen:
example[0]
# Ergebnis: 'H'
example[1]
# Ergebnis: 'a'
# Vorletztes und letztes Zeichen:
example[-2]
# Ergebnis: 'l'
example[-1]
# Ergebnis: 't'
Der Index-Operator kann ebenso genutzt werden, um Bereiche („Slices“) einer
Zeichenkette auszugeben. Hierzu werden in den eckigen Klammern zwei Index-Zahlen
n_1 und n_2 durch einen Doppelpunkt getrennt angegeben. Es muss dabei
allerdings beachtet werden, dass in Python bei Bereichsangaben die obere Grenze
nicht im Bereich eingeschlossen ist:
example[0:5]
# Ergebnis: 'Hallo'
example[6:-1]
# Ergebnis: 'Wel'
example[6:]
# Ergebnis: 'Welt'
Lässt man von der Bereichsangabe die Zahl vor oder nach dem Doppelpunkt weg, so wird die Zeichenkette von Beginn an beziehungsweise bis zum Ende ausgegeben.
Bei der Verwendung von Slices kann optional noch ein dritter Parameter angegeben werden, der die „Schrittweite“ festlegt, also angibt, jedes wie vielte Zeichen ausgewählt werden soll:
example[::2]
# Ergebnis: 'HloWl'
Wird für die Schrittweite ein negativer Wert angegeben, so wird der String von hinten nach vorne abgearbeitet.
String-Funktionen¶
Für Zeichenketten gibt es in Python einige Funktionen, die in der Form
zeichenkette.funktionsname() angewendet werden können.
Suchen von Teilstrings
Mittels des in-Operators kann geprüft werden, ob ein Teilstring in einer
anderen Zeichenkette enthalten ist:
'all' in 'Hallo'
# Ergebnis: True
Möchte man eine Zeichenkette nicht nur hinsichtlich der Existenz eines
Teilstrings prüfen, sondern auch wissen, wie oft dieser darin enthalten ist,
kann die Funktion count() verwendet werden:
# Anzahl des Buchstabens 'l' im Wort 'Hallo':
'Hallo'.count('l')
# Ergebnis: 2
Der Funktion count() können als weitere Argumente eine Start- und eine
Stopp-Position übergeben werden, wenn nicht die ganze Zeichenkette, sondern nur
ein bestimmter Abschnitt durchsucht werden soll:
# Anzahl des Buchstabens 'l' in den ersten drei Buchstaben von 'Hallo':
'Hallo'.count('l', 0, 3)
# Ergebnis: 1
Wie allgemein in Python üblich, wird bei Bereichsangaben die untere Grenze ins
Intervall aufgenommen, die obere nicht; im obigen Beispiel werden daher nur die
drei Indexnummern 0, 1 und 2 geprüft. Mit der gleichen Sytanx kann
mittels der Funktion find() die Index-Position des ersten Vorkommens eines
Teilstrings innerhalb der Zeichenkette angezeigt werden:
'Hallo'.find('l')
# Ergebnis: 2
'Hallo'.find('l', 2, 4)
# Ergebnis: 3
Soll die Suche nicht „von links“, sondern „von rechts“ aus erfolgen, kann die
Funktion rfind() genutzt werden; sie gibt als Ergebnis den Index des
letzten Vorkommens des angegebenen Teilstrings zurück. Wird der gesuchte
String im Zielstring nicht gefunden, liefern die Funktionen find() und
rfind() den Wert -1 als Ergebnis zurück.
Soll nur die Endung einer Zeichenkette untersucht werden, beispielsweise
bei der Prüfung eines Dateityps, so kann anstelle der Funktion rfind()
noch besser die Funktion endswith() genutzt werden. Diese liefert genau
dann als Ergebnis True zurück, wenn die Zeichenkette mit dem angegebenen
Teilstring endet.
In gleicher Weise wie endswith() gibt die Funktion startswith() als
Ergebnis True zurück, wenn die Zeichenkette mit dem angegebenen Teilstring
beginnt. Beide Funktionen liefern andererseits False als Ergebnis.
Komplexere Suchmuster sind mit Hilfe von regulären Ausdrücken und den
zugehörigen Funktionen aus dem re-Modul möglich.
Ersetzen von Teilstrings
Zeichenketten sind unveränderbar. Daher kann der Index-Operator nicht auf der
linken Seite des Zuweisungsoperators = stehen; beispielsweise würde die
Eingabe von 'Hallo Welt'[0:5] = 'Salut' einen TypeError erzeugen. Um eine
solche Veränderung vorzunehmen, kann jedoch beispielsweise die speziell für
Zeichenketten definierte replace()-Funktion genutzt werden, und der daraus
resultierende String wieder der ursprünglichen Variable zugewiesen werden:
# 'Hallo' durch 'Salut' ersetzen:
example = 'Hallo Welt!'.replace('Hallo', 'Salut')
Komplexere Ersetzungen sind mit Hilfe von regulären Ausdrücken und den
zugehörigen Funktionen aus dem re-Modul möglich.
Groß- und Kleinschreibung ändern
Python achtet bei der Behandlung von Zeichenketten auf die Groß- und
Kleinschreibung. Sollen also beispielsweise zwei Wörter hinsichtlich nur ihres
Inhalts, nicht jedoch hinsichtlich der Groß- und Kleinschreibung verglichen
werden, so werden üblicherweise beide zunächst in Kleinbuchstaben umgewandelt.
Hierfür kann die Funktion lower() verwendet werden:
'Hallo'.lower() == 'hallo'
# Ergebnis: True
Die Funktion upper(), wandelt in umgekehrter Weise alle Buchstaben einer
Zeichenkette in Großbuchstaben um. Zwei ähnliche Funktionen sind capitalize(),
bei einer Zeichenkette nur den ersten Buchstaben als Großbuchstaben und die
restlichen als Kleinbuchstaben ausgibt sowie title(), die bei jedem Wort
einer Zeichenkette den ersten Buchstaben als Großbuchstaben und die übrigen als
Kleinbuchstaben ausgibt. Mit swapcase() können zudem alle Großbuchstaben
einer Zeichenkette in Kleinbuchstaben und umgekehrt umgewandelt werden.
Leerzeichen entfernen, Text zentrieren
Mittels der Funktionen lstrip() oder rstrip() können Leerzeichen am
Anfang oder am Ende einer Zeichenkette entfernt werden; mittels strip()
werden Leerzeichen sowohl am Anfang wie auch am Ende einer Zeichenkette
entfernt.
Die Funktion rstrip() wird häufig eingesetzt, um beim Einlesen einer
Textdatei alle Leerzeichen am Ende der einzelnen Zeilen zu entfernen.
Mittels der Funktion center() kann eine Zeichenkette umgekehrt über eine
bestimmte Textbreite zentriert ausgegeben werden. Beispielsweise gibt
'Hallo'.center(20) als Ergebnis die Zeichenkette ' Hallo '
zurück. Eine derartige Formatierung kann beispielsweise für eine tabellarische
Ausgabe von Daten nützlich sein.
Aufteilen und Zusammenfügen von Zeichenketten
Mittels der Funktion split() kann eine Zeichenkette in eine Liste von
Teilstrings aufgeteilt werden. Als Argument wird dabei üein Zeichen oder eine
Zeichenfolge angegeben, gemäß der die Aufteilung erfolgen soll. Verwendet man
beispielsweise als Trennzeichen das Leerzeichen ' ', so wird die
Zeichenkette in einzelne Wörter aufgeteilt.
# Zeichenkette aufteilen:
'Hallo Welt'.split(' ')
# Ergebnis: ['Hallo', 'Welt']
Wird die Funktion split() ohne Trennzeichen als Argument aufgerufen, so wird
die Zeichenkette an allen Whitespace-Zeichen aufgetrennt. So kann beispielsweise
mit len( text.split() ) die Anzahl der Wörter in einer Zeichenkette
gezählt werden.
# Zeichenkette zusammenfügen:
' '.join(['Hallo', 'Welt'])
# Ergebnis: 'Hallo Welt'
Umgekehrt kann mittels der Funktion join() eine Liste von Teilstrings zu
einer einzigen Zeichenkette zusammengesetzt werden. Dabei wird zunächst in der
Zeichenkette ein Verbindungszeichen (oder eine Folge von Verbindungszeichen)
angegeben, als Argument der join()-Funktion wird dann die Liste der zu
verknüpfenden Teilstrings übergeben.
Formatierung von Zeichenketten
Bisweilen mag man beispielsweise mit print() den Wert einer Variablen als
Teil einer Zeichenkette ausgeben. Zu diesem Zweck können in die Zeichenkette
Platzhalter eingebaut werden, die dann durch die gewünschten Werte ersetzt
werden. Dies funktioniert der „klassischen“ Methode nach (wie etwa in C) so:
var = 5829
'Der Wert von var ist %s.' % var
# Ergebnis: 'Der Wert von var ist 5829.'
Sollen an mehreren Stellen Ersetzungen vorgenommen werden, werden die Platzhalter in der gleichen Reihenfolge durch die Elemente eines gleich langen Variablen-Tupels ersetzt:
var_1 = 8913
var_2 = 7824
print('Der Wert von var_1 ist %s, \
der Wert von var_2 ist %s' % (var_1, var_2) )
# Ergebnis: 'Der Wert von var_1 ist 8913, der Wert von var_2 ist 7824.'
Nach der neueren, mehr pyton-artigen Variante können Ersetzungen in
Zeichenketten auch mittels der Funktion format() vorgenommen werden:
var = 5829
var_1 = 8913
var_2 = 7824
print( 'Der Wert von var ist {}.\n'.format(var) )
# Ergebnis: 'Der Wert von var ist 5829.'
print( 'Der Wert von var_1 ist {}, \
der Wert von var_2 ist {}.\n'.format(var_1, var_2) )
In diesem Fall werden die geschweiften Klammern innerhalb der Zeichenkette als
Platzhalter angesehen und durch die als Argumente der Funktion format()
angegebenen Variablen ersetzt. Als einzige Besonderheit müssen bei dieser
Methode „echte“ geschweifte Klammern, die als Textsymbole in der Zeichenkette
vorkommen sollen, durch {{ bzw. }} dargestellt werden.
Eine komplette Liste an möglichen Format-Angaben findet sich in der offiziellen Python-Dokumentation.
Sonstiges:
Eine vollständige Liste an String-Funktionen erhält man, indem man
die Funktion dir() auf einen beliebigen String anwendet, beispielsweise
dir(string_1). Nähere Informationen können dann beispielsweise mittels
help(string_1.replace) aufgerufen werden.
list und tuple – Listen und Tupel¶
Listen und Tupel dienen der Sequenzierung von Objekten beliebigen Datentyps. Sie können unterschiedliche Datentypen in beliebiger Reihenfolge beinhalten. Listen werden in Python durch eckige Klammern, Tupel durch runde Klammern gekennzeichnet; die einzelnen Elemente werden durch jeweils ein Komma-Zeichen voneinander getrennt.
liste_1 = ['a', 'b', 'c', 1, 2, 3] # oder: list( 'a', 'b', 'c', 1, 2, 3 )
tupel_1 = ('a', 'b', 'c', 1, 2, 3) # oder: tuple( ['a', 'b', 'c', 1, 2, 3] )
Der einzige Unterschied zwischen Listen, die mit [ und ] gekennzeichnet
sind, und Tupeln, deren Elemente zwischen ( und ) stehen, liegt darin,
dass die Inhalte von Listen verändert werden können, während die Inhalte von
Tupeln unveränderbar sind. [3] Tupel können genutzt werden, um die Datensicherheit
bestimmter Variablen, die an verschiedenen Stellen eines Programms genutzt
werden, zu gewährleisten; im allgemeinen werden jedoch bevorzugt Listen
genutzt.
Mittels der Schlüsselwörter in beziehungsweise not in kann geprüft
werden, ob ein Objekt in einer Liste enthalten ist oder nicht:
'a' in liste_1
# Ergebnis: True
Indizierung von Listen und Tupeln¶
Auf die einzelnen Elemente einer Liste kann mit Hilf des mit Hilfe des
Index-Operators [ ] zugegriffen werden. Die Syntax stimmt mit der
Indizierung von Zeichenketten überein, da
es sich bei diesen letztlich ebenfalls um Listen einzelner Buchstaben handelt:
# Erstes und zweites Element der Liste:
liste_1[0]
# Ergebnis: 'a'
liste_1[1]
# Ergebnis: 'b'
# Vorletztes und letztes Element der Liste:
liste_1[-2]
# Ergebnis: '2'
liste_1[-1]
# Ergebnis: '3'
Bereiche („Slices“) einer Liste können mit Hilfe des Index-Operators ausgewählt
werden, indem man zwei mit einem Doppelpunkt getrennte Index-Zahlen n1 und
n2 angibt; dabei muss beachtet werden, dass in Python bei Bereichsangaben
die obere Grenze nicht im Bereich eingeschlossen ist:
liste_1[3:5]
# Ergebnis: [1, 2]
Wird bei der Verwendung von Slices die obere und/oder die untere Bereichsangabe weggelassen, so werden die Elemente vom Anfang an beziehungsweise bis zum Ende hin ausgewählt. Ebenso wie bei Zeichenketten kann zudem ein dritter Parameter angegeben werden, der festlegt, jedes wie vielte Element ausgewählt werden soll:
liste_1[1:5:2]
# Ergebnis: ['a', 'c', 2]
Ist der Wert des dritten Parameters negativ, so wird die Liste von hinten nach vorne abgearbeitet.
Mehrdimensionale Listen
Listen können „verschachtelt“ sein, eine Liste kann also weitere Listen als Elemente beinhalten. Durch eine derartige Struktur könnten beispielsweise die Werte einer Tabelle gespeichert werden, die aus mehreren Zeilen besteht, wobei jede Zeile wiederum mehrere Spalten enthält.
Bei der Indizierung von verschachtelten Listen kann der Index-Operator mehrmals hintereinander angewendet werden:
liste_3 = [ ['a','b','c'], ['d','e','f'], ['g','h','i'] ]
# Zweites Listenelement ('Zeile') auswählen:
liste_3[1]
# Ergebnis: ['d','e','f']
# Drittes Element ('Spalte') dieser Zeile auswählen:
liste_3[1][2]
# Ergebnis: 'f'
Durch die erste Indizierung wird im obigen Beispiel eine Teilliste ausgewählt; auf diese Liste als Ergebnis der ersten Indizierung kann erneut der Indexoperator angewendet werden, um ein darin enthaltenes Element (oder auch einen Bereich) auszuwählen.
Listen-Funktionen¶
Für Listen existieren Funktionen, die in der Form liste.funktionsname()
angewendet werden können.
Listen verknüpfen
Durch liste_1.extend(liste2) können zwei Listen miteinander kombiniert
werden:
liste_1 = [1, 2, 3]
liste_2 = [4, 5, 6]
liste_1.extend(liste_2)
liste_1
# Ergebnis: [1, 2, 3, 4, 5, 6]
Durch die Funktion extend() wird die erste Liste um die Elemente der zweiten
Liste erweitert; die Funktion extend() selbst liefert den Wert None als
Ergebnis zurück. Möchte man eine derartige neue Liste erstellen, ohne dabei die
ursprünglichen Listen zu verändern, kann der +-Operator verwendet werden:
liste_1 = [1, 2, 3]
liste_2 = [4, 5, 6]
liste3 = liste_1 + liste_2
liste_1
# Ergebnis: [1, 2, 3]
liste_2
# Ergebnis: [4, 5, 6]
liste_3
# Ergebnis: [1, 2, 3, 4, 5, 6]
Ebenso kann beispielsweise mittels 3 * liste_1 eine Liste erzeugt werden,
die aus einer dreifachen Wiederholung der liste_1 besteht:
liste_4 = 3 * liste_1 ; liste_4
# Ergebnis: [1, 2, 3, 1, 2, 3, 1, 2, 3]
Möchte man eine zweite Liste als eigenes Element zu einer Liste hinzufügen, so
kann die Funktion append() verwendet werden:
liste_1.append(liste_2)
# Ergebnis: [1, 2, 3, [4, 5, 6]]
Listen sortieren
Mittels der Funktion sort() können die Elemente einer Liste in aufsteigender
Reihenfolge, mittels reverse() in absteigender Reihenfolge sortiert werden:
liste_5 = [3, 1, -5, 8, 2]
# Liste sortieren:
liste_5.sort()
liste_5
# Ergebnis: [-5, 1, 2, 3, 8]
liste_5.reverse()
liste_5
# Ergebnis: [8, 3, 2, 1, -5]
Elemente indizieren, einfügen und entfernen
Um zu prüfen, wie häufig ein bestimmtes Element in einer Liste enthalten ist,
kann die Funktion count() angewendet werden:
liste_1.count(3)
# Ergebnis: 1
Soll nur geprüft werden, ob ein Element in einer Liste enthalten ist, so kann
auch das Schlüsselwort in verwendet werden; im obigen Beispiel könnte somit
3 in liste_1 geschrieben werden, um zu prüfen, ob das Element 3 in der
Liste vorkommt.
Die Position (des ersten Auftretens) eines Elements innerhalb einer Liste kann
mittels der Funktion index() bestimmt werden: [4]
liste_1.index(3)
# Ergebnis: 2
Demnach kann der Wert 3 im obigen Beispiel mittels liste_1[2] aufgerufen
werden und ist somit das dritte Element der Liste. Vor der Verwendung von
index() sollte allerdings mittels if element in liste: stets geprüft
werden, ob sich das Element in der Liste befindet, da ansonsten ein
ValueError auftritt.
Mittels insert(indexnummer, element) kann ein neues Element
vor der angegebenen Indexnummer eingefügt werden:
# Neues Element vor dem dritten Element (Index 2) einfügen:
liste_1.insert(2, 'Hallo')
liste_1
# Ergebnis: [1, 2, 'Hallo', 3]
Mittels remove(element) oder pop(indexnummer) können Elemente wieder aus
der Liste entfernt werden:
# Element 'Hallo' aus Liste entfernen:
liste_1.remove('Hallo')
# Drittes Element entfernen:
liste_1.pop(2)
liste_1
# Ergebnis: [1, 2]
Beim Aufruf der pop()-Funktion wird das aus der Liste entfernte Objekt als
Ergebnis zurückgegeben, was beispielsweise in „Stacks“ durchaus erwünscht ist.
Das Löschen eines Listenbereichs zwischen zwei Indexnummern ist mittels del
liste[n1:n2] möglich; auch bei dieser Bereichsangabe wird die obere Grenze
nicht mit eingeschlossen.
Zu beachten ist wiederum, dass remove() einen ValueError auslöst, wenn
sich das zu entfernende Element nicht in der Liste befindet, und pop() einen
IndexError auslöst, wenn die Liste kürzer als die angegebene Indexnummer
oder leer ist.
Listen kopieren
Listen können nicht einfach mittels des Zuweisungsoperators kopiert werden. Versucht man dies, so wird lediglich eine neue Referenz erstellt, die auf die gleiche Liste zeigt und die Inhalte der ursprünglichen Liste verändern kann:
# Liste erstellen:
liste_1 = [0,1,2,3,4,5]
# Neue Referenz auf die Liste:
liste_2 = liste_1
# Liste mittels der Referenz ändern:
liste_2[0] = 1
# Test:
liste_1
# Ergebnis: [1, 1, 2, 3, 4, 5]
Der Grund für dieses scheinbar seltsame Verhalten des Python-Interpreters liegt darin, dass auf diese Weise Listen direkt verändert werden können, wenn sie als Argumente an Funktionen übergeben werden. Da dies wesentlich häufiger vorkommt als das „echte“ Kopieren einer Liste, ist es in Python der Standard.
Um eine echte Kopie einer Liste zu erstellen, muss die Funktion copy() auf
die ursprüngliche Liste angewendet werden:
# Liste erstellen:
liste_1 = [0,1,2,3,4,5]
# Kopie der Liste erstellen:
liste_2 = liste_1.copy()
Werden jetzt die Inhalte der zweiten Liste geändert, so bleiben die Inhalte der ersten Liste bestehen.
List-Comprehensions¶
Mit Hilfe so genannter List-Comprehensions können aus bestehenden Listen neue Listen erzeugt werden; dabei können beispielsweise Filter auf die die Elemente der bestehenden Liste angewendet werden; ebenso ist es möglich, Funktionen auf alle Elemente der bestehenden Liste anzuwenden und die jeweiligen Ergebnisse in der neuen Liste zu speichern.
Beispiele:
Alle Elemente einer bestehenden Liste sollen quadriert werden:
# Ausgangsliste erstellen: alte_liste = [1, 2, 3, 4, 5] # List Comprehension anwenden: neue_liste = [i**2 for i in alte_liste] neue_liste # Ergebnis: [1, 4, 9, 16, 25]
In diesem Beispiel wird für jedes Element der bestehenden Liste, das jeweils mit einer temporären Variablen
ibezeichnet wird, der Quadratwerti**2berechnet und das Ergebnis als neue Liste gespeichert.Aus einer bestehenden Liste sollen alle geradzahligen Werte ausgewählt werden:
# Ausgangsliste erstellen: alte_liste = [1, 2, 3, 4, 5] # List Comprehension anwenden: neue_liste = [i for i in alte_liste if i % 2 == 0] neue_liste # Ergebnis: [2, 4]
In diesem Beispiel werden die Elemente der bestehenden Liste, wiederum kurz mit
ibezeichnet, unverändert in die neue Liste aufgenommen, sofern sie die angegebene Bedingungi % 2 == 0erfüllen.Aus zwei bestehenden Listen sollen alle Elemente ausgewählt werden, die in beiden Listen enthalten sind:
# Ausgangslisten erstellen: liste_1 = [1, 2, 3, 4, 5] liste_1 = [2, 3, 4, 5, 6] # List Comprehension anwenden: gemeinsame_elemente = [i for i in liste_1 if i in liste_2] gemeinsame_elemente # Ergebnis: [2, 3, 4, 5]
In diesem Beispil wird mittels der temporären Variablen
ischrittweise geprüft, ob die Elemente der ersten Liste auch in der zweiten Liste enthalten sind und gegebenenfalls in die neue Liste aufgenommen.Die Werte zweier Listen sollen elementweise miteinander multipliziert werden:
# Ausgangslisten erstellen: liste_1 = [1, 2, 3, 4, 5] liste_2 = [2, 3, 4, 5, 6] # List Comprehension anwenden: produkte = [liste_1[i] * liste_2[i] for i in range(5)] produkte # Ergebnis: [2, 6, 12, 20, 30]
In diesem Beispiel wurde mit Hilfe der Funktion range() ein Bereich an ganzen Zahlen festgelegt, den die Variable
idurchlaufen soll. Die Variableibezeichnet in diesem Fall also nicht ein konkretes Element einer Liste, sondern vielmehr eine Indexnummer; mittels dieser Indexnummer kann dann auf die Elemente der Ausgangslisten zugegriffen werden.Auch eine zusätzliche if-Bedingung, beispielsweise
if liste_1[i] > 2wäre in diesem Fall möglich, würde logischerweise aber zu einem anderen Ergebnis führen.
List Comprehensions ermöglichen es allgemein, neue Listen schnell und gut lesbar zu erzeugen.
set und frozenset – Mengen¶
Ein Set bezeichnet in Python eine Menge an Objekten beliebigen Datentyps, wobei jedes Objekt nur ein einziges Mal in der Menge enthalten sein darf. Sets werden in Python in geschweifte Klammern gesetzt: Durch Anwendung von Operatoren auf paarweise je zwei Sets können – entsprechend den Regeln der Mengenlehre – neue Sets gebildet werden.
set_1 = {'a', 'b', 'c', 1, 2, 3} # oder: set( ['a', 'b', 'c', 1, 2, 3] )
set_2 = {'b', 'c', 'd', 2, 3, 4}
# Schnittmenge:
set_1 & set_2
# Ergebnis: {'b', 'c', 2, 3}
# Vereinigungsmenge:
set_1 | set_2
# Ergebnis: {'a', 'b', 'c', 'd', 1, 2, 3, 4}
# Differenzmenge:
set_1 \ set_2
# Ergebnis: {'a', 1}
# Symmetrische Differenz (Entweder-Oder):
set_1 ^ set_2
# Ergebnis: {'a', 1, 4, 'd'}
# Test, ob set_1 eine Obermenge von set_2 ist:
set_1 > set_2
# Ergebnis: False
Mengen können unter anderem dazu genutzt werden, um aus einer Liste alle mehrfach vorkommenden Elemente heraus zu filtern. Hierzu wird etwa folgende Syntax genutzt:
any_list = ['a', 'a', 'b', 'c', 1, 2, 2, 3]
list_with_unique_elements = list(set(any_list))
# Ergebnis: ['a', 'b', 'c', 1, 2, 3]
Zum Arbeiten mit Mengen sind zusätzlich folgende Funktionen nützlich:
- Mit der
add()-Funktion lassen sich Elemente zu einer Menge hinzufügen, beispielsweisemy_set.add('x'). - Mit der
discard()-Funktion lassen sich Elemente aus einer Menge entfernen, beispielsweisemy_set.discard('x'). - Mit der
copy()-Funktion kann eine Kopie einer Menge erstellt werden, beispielsweisemy_set2 = my_set_.copy(). - Mit der
clear()-Funktion können alle Elemente einer Menge gelöscht werden, beispielsweisemy_set2.clear().
Neben üblichen Sets können mittels der Funktion frozenset() auch
unveränderliche Listen erzeugt werden.
dict – Wörterbücher¶
In Python existiert ein weiterer Datentyp für Schlüssel-Wert-Paare. Ein
solches dict ist somit aufgebaut wie ein Wörterbuch, das zu jedem Eintrag
(Schlüssel) eine passende Erläuterung (Wert) liefert.
Zur Darstellung von dicts werden in Python geschweifte Klammern verwendet.
Als Schlüssel werden meist strings genutzt, die zugehörigen Werte werden
durch einen Doppelpunkt getrennt angegeben. Die einzelnen Schlüssel-Wert-Paare
werden – wie die Elemente einer Liste – mit je einem Komma voneinander
getrennt aufgelistet.
# Beispiel:
address-book = {
name_1 : adresse_1,
name_2 : adresse_2,
name_3 : adresse_3,
...
}
Anstelle von Zeichenketten können auch Zahlen oder andere unveränderbare Objekte genutzt werden – beispielsweise Tupel. Veränderbare Objekttypen wie beispielsweise Listen sind hingegen als Schlüssel nicht erlaubt.
Auf die einzelnen Werte eines dicts kann mittels des Index-Operators
zugegriffen werden, wobei jedoch nicht ein numerischer Wert, sondern der Name
eines Schlüssels in den eckigen Klammern angegeben wird:
address-book[name_1]
# Ergebnis: adresse_1
Mittels der dict-Funktionen keys(), values() und items() lassen
sich so genannte „Views“ eines Wörterbuchs erzeugen. Bei einem View handelt es
sich um eine Listen-Variable, die automatisch aktualisiert wird, wenn das
zugehörige dict geändert wird.
| Funktion | Ergebnis | Beschreibung |
anydict.keys() |
[key_1, key_2, ...] |
Liste mit allen Schlüsseln |
anydict.values() |
[value_1, value_2, ...] |
Liste mit allen Werten |
anydict.items() |
[(key_1, value_1), (key_2, value_2), ...] |
Liste von Schlüssel-Wert-Tupeln |
Mit key_1 in anydict kann geprüft werden, ob der Schlüssel key_1 im
Wörterbuch anydict vorhanden ist (Ergebnis: True oder False).
Um den zum Schlüssel key_1 gehörigen Wert von anydict auszugeben, kann
der Index-Operator [ ] genutzt werden:
anydict[key_1]
# Ergebnis: value_1 oder Error
Ist der Schlüssel nicht vorhanden, wird ein KeyError ausgelöst. Möchte
man dies verhindern, so kann man folgenden Code nutzen:
anydict.get(key_1, default=None)
# Ergebnis: value_1 oder None
Mittels der dict-Funktion get() können Dictionaries auch als „Zähler“
genutzt werden: Soll beispielsweise festgehalten werden, wie häufig einzelne
Worte in einem Text vorkommen, so legt man zunächst mittels wortanzahl =
dict() ein neues dict an; anschließend kann wortweise geprüft werden, ob
dieses Wort bereits als Schlüssel im dict enthalten ist. Ist dies der Fall,
so wird der zugehörige „Counter“-Wert um 1 erhöht, andernfalls wird ein
neuer Schlüssel mit dem Wert 1 angelegt. Ist das zu prüfende Wort in der
Variable wort gespeichert, so genügt für die genannte Aufgabe bereits ein
Einzeiler:
# Prüfen, ob Wort bereits im Dict enthalten ist;
# Counter um 1 erhöhen
wortanzahl[wort] = wortanzahl.get(wort, 0) + 1
file – Dateien¶
Datei-Objekte stellen in Python die Hauptschnittstelle zu externen Dateien auf dem Computer dar. Sie können genutzt werden, um Dateien beliebigen Typs zu lesen oder zu schreiben.
Datei-Objekte werden erzeugt, indem man die Funktion open() aufruft, und
dabei den Namen der Datei sowie ein Kürzel für den gewünschten
Bearbeitungsmodus angibt:
myfile = open('file.txt', 'r')
Als Bearbeitungsmodus kann 'r' (lesen), 'w' (schreiben) oder 'rw'
(lesen und schreiben) gewählt werden. Sollen binäre Dateien gelesen
beziehungsweise geschrieben werden, muss an das jeweilige Kürzel ein b
angehängt werden, beispielsweise bezeichnet 'rb' den Lesemodus einer
binären Datei.
Einlesen von Dateien
Wird eine Datei im Lesemodus geöffnet, so kann sie beispielsweise mittels der
Funktion read() im Ganzen als ein einziger String eingelesen werden:
# Datei als einzelnen String einlesen:
long_string = myfile.read()
Diese Methode ist für größere Dateien nicht empfehlenswert. Besser ist es,
mittels der Funktion readline() eine Datei Zeile für Zeile einzulesen.
Bei jedem solchen Aufruf wird die jeweils eingelesene Zeile als Ergebnis
zurückgegeben und der „Cursor“ für die aktuelle Position in der Datei auf die
nächste Zeile gesetzt. Mit der Funktion readlines() wird die Datei
zeilenweise in eine Liste von Zeichenketten eingelesen.
Noch einfacher ist ein zeilenweises Einlesen, indem die Datei-Variable selbst als iterierbares Objekt an eine for-Schleife übergeben wird:
# Schleife über alle Zeilen der Datei:
for line in myfile:
# Gib die aktuelle Zeile aus:
print(line)
Am Ende eines Lesezugriffs sollte die Datei mittels close(myfile) wieder
geschlossen werden.
Schreiben in Dateien
Um Text in eine Datei zu schreiben, wird diese zunächst im Schreibmodus geöffnet:
myfile = open('file.txt', 'w')
Anschließend kann mittels der Funktion write() eine (gegebenenfalls auch
mehrzeilige) Zeichenkette in die Datei geschrieben werden:
myfile.write('Hallo Welt!\n')
Zudem kann mittels myfile.writelines(stringliste) kann eine Liste von
einzelnen Zeichenketten in eine Datei geschrieben werden. Die einzelnen
Zeichenketten werden bei write() als auch bei writelines()
geschrieben „wie sie sind“, es muss also bei Bedarf ein Zeilenende-Zeichen
\n am Ende der zu schreibenden Zeichenkette(n) sein, damit auch in der
geschriebenen Datei an der jeweiligen Stelle ein Zeilenumbruch erfolgt.
Am Ende eines Schreibzugriffs muss die Datei mittels close(myfile) wieder
geschlossen werden, da nur dann das Datei-Attribut mtime
(„Modifikationszeit“) korrekt gesetzt wird.
Da während des Einlesens oder Schreibens von Dateien prinzipiell auch mit
Fehlern gerechnet werden muss, müsste stets mittels try..except..finally ein
Ausnahme-Handling eingebaut werden. Eine (bessere) Alternative hierzu
beziehungsweise zum manuellen Schließen eines file-Objekts besteht darin,
ein with-Statement mit folgender Syntax zu verwenden:
with open("file.txt", 'r') as myfile:
for line in myfile:
print(line)
Mit dieser Variante wird die Datei automatisch geschlossen, auch wenn beim Lesen oder Schreiben ein Fehler aufgetreten ist.
Anmerkungen:
| [1] | In der Mathematik wird die imaginäre Einheit meist mit 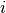 bezeichnet, in der Elektrotechnik wird hingegen oft
bezeichnet, in der Elektrotechnik wird hingegen oft 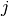 verwendet.
In Python kann sowohl verwendet.
In Python kann sowohl j als auch J als Symbol für die imaginäre
Einheit geschrieben werden. |
| [2] | Python behandelt einfache und doppelte Anführungszeichen gleichwertig, anders als beispielsweise die Linux-Shell. Innerhalb eines Strings, der in einfache Anführungszeichen gesetzt wird, können doppelte Anführungszeichen vorkommen und umgekehrt. Sollen einfache Anführungszeichen in einem String vorkommen, der ebenfalls
durch einfache Anführungszeichen begrenzt ist, so muss vor die inneren
Anführungszeichen jeweils ein Backslash ( |
| [3] | Genau genommen sind bei einem Tupel (oder auch einem frozenset) nur
die Referenzen auf die enthaltenen Objekte unveränderlich. Enthält ein Tupel
beispielsweise als erstes Argument eine Liste namens l, so kann dieser
mittels l.insert(0, 'Hallo!') ein neues Element hinzugefügt werden. Das
Tupel ändert sich dabei nicht, da die ID der Liste l unverändert bleibt. |
| [4] | Die Funktionen count() und index() sind die einzigen beiden
Listenfunktionen, die auch für die unveränderlichen Tupel definiert sind. |